Abstract
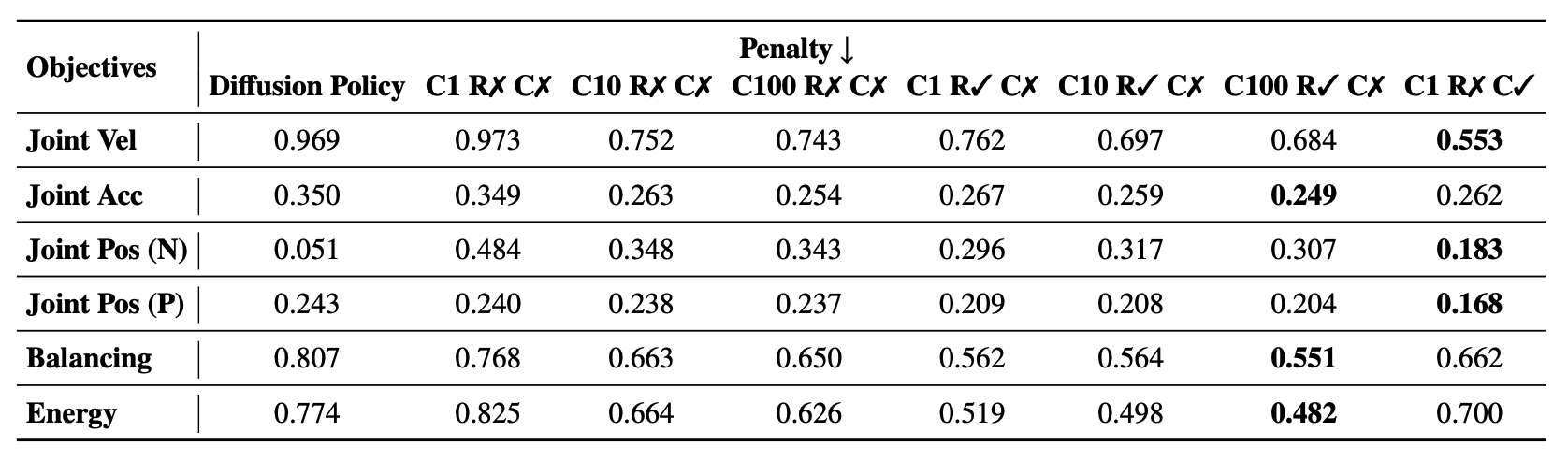
Legged locomotion demands controllers that are both robust and adaptable, while remaining compatible with task and safety considerations. However, model-free reinforcement learning (RL) methods often yield a fixed policy that can be difficult to adapt to new behaviors at test time. In contrast, Model Predictive Control (MPC) provides a natural approach to flexible behavior synthesis by incorporating different objectives and constraints directly into its optimization process. However, classical MPC relies on accurate dynamics models, which are often difficult to obtain in complex environments and typically require simplifying assumptions. We present Diffusion-MPC, which leverages a learned generative diffusion model as an approximate dynamics prior for planning, enabling flexible test-time adaptation through reward and constraint based optimization. Diffusion-MPC jointly predicts future states and actions; at each reverse step, we incorporate reward planning and impose constraint projection, yielding trajectories that satisfy task objectives while remaining within physical limits. To obtain a planning model that adapts beyond imitation pretraining, we introduce an interactive training algorithm for diffusion based planner: we execute our reward-and-constraint planner in environment, then filter and reweight the collected trajectories by their realized returns before updating the denoiser. Our design enables strong test-time adaptability, allowing the planner to adjust to new reward specifications without retraining. We validate Diffusion-MPC on real world, demonstrating strong locomotion and flexible adaptation.